Anthropic's Claude Mythos Preview system card signals a real frontier shift: a model strong enough in cyber tasks that the lab chose restricted release over broad commercial access.
The easiest agent demo is the clean one: a user asks for something, the model chooses the right tool, the tool returns a valid response, and the agent...
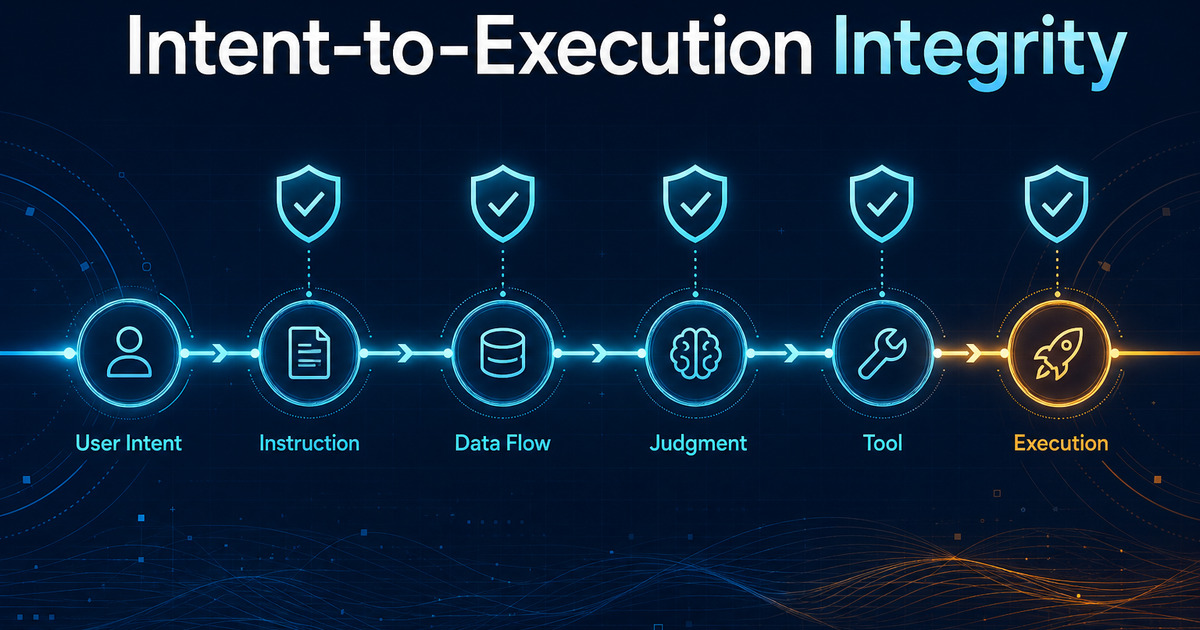
The agent-safety conversation is shifting. For the last year, most teams have asked whether a model can follow instructions, resist prompt injection,...
The easiest way to make an AI automation roadmap look sophisticated is to add more agents. A planner agent. A researcher agent. A critic agent. A tool...
Most enterprise agent demos still start in the browser. The agent opens a page, reads the interface, clicks a button, waits for a spinner, misreads a...
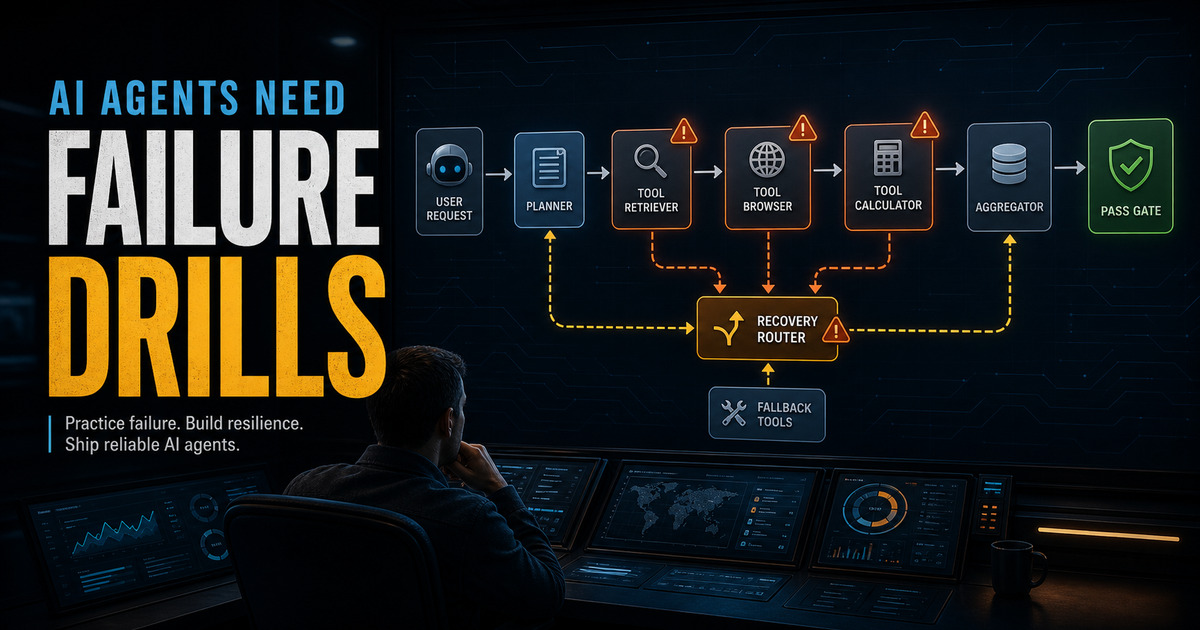
When an AI agent fails at a real workflow, the usual reflex is to reach for a stronger model. Bigger context window. More reasoning. A longer system...
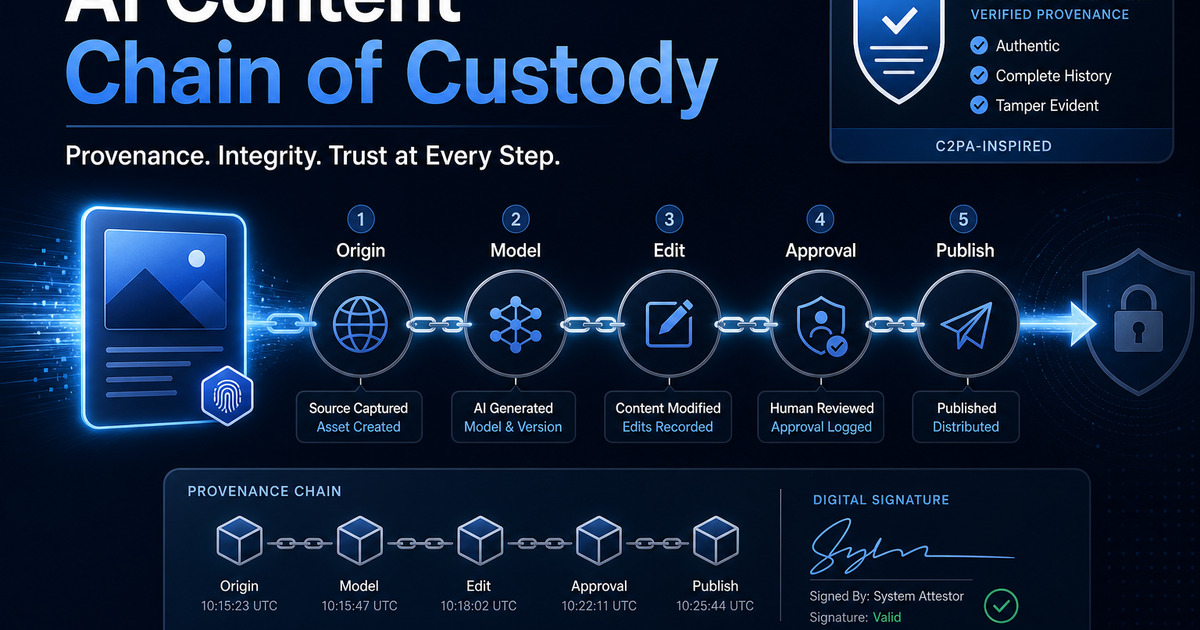
The uncomfortable question after an AI agent incident is rarely, “Did the dashboard show activity?” It is usually much more basic: “Can we reconstruct...
A watermark is a useful signal, but it is a thin one. It can help answer, “Was this asset generated or altered by a known system?” It does not answer...
A good chef does not begin dinner service by rummaging through the pantry, discovering the menu mid-order, and hoping the oven has the right settings....
A benchmark score is a resume. It tells you something useful about the candidate, but it does not tell you how they behave on their first day inside...
The most seductive enterprise AI demo is still the simplest one: open a chat box, ask a business question, and watch the system query company data like...
A chatbot can be wrong in a familiar way: it says something false, omits a caveat, or gives a weak recommendation. An agent can be wrong with a shell,...
Anthropic’s new survey of quantitative social scientists is easy to read as an academic labor story. Economists are adopting coding agents faster than...
A support agent gets a refund request, apologizes nicely, confirms the amount, names the right policy, and closes with a warm sign-off. The transcript...
Most agent demos succeed for an unremarkable reason: the room is familiar. The agent has, in effect, seen the furniture before. Book the trip, update...
Ask a personal agent to do something boring — book a flight, move money between accounts, reply to a customer, generate an invoice — and watch how it...
Plugging an agent into your tools has never been easier. The [Model Context Protocol](https://modelcontextprotocol.io/docs/getting-started/intro) gives...
Picture a support agent wired into your stack. A customer asks it to update a shipping address. The agent reads the ticket, pulls the order, edits the...
There is a quiet assumption baked into how most teams evaluate AI agents: that running the benchmark is basically free, the way running a unit test is...
A bigger context window makes a single conversation cheaper to run. It does not tell you what your agent learned last Tuesday, whether that lesson was...
There is an uncomfortable failure mode in agentic systems that most evaluation dashboards are blind to. It is not that the model refuses the task. It...
For most of the last few years, the mental model for an AI assistant was a conversation. You typed something, it answered, and the worst-case outcome...
It is Tuesday morning and your support agent did something. A refund was issued, a ticket was reclassified, a CRM row was updated, and a customer is...
Coding agents are turning into filesystem actors. They open shells, edit repos, install dependencies, and run arbitrary scripts on machines you care...
A tool-using agent starts out simple. Give the model a calculator, a database query function, a few scripts, maybe a browser, and let it route between...
The uncomfortable part of deploying useful agents is not that they can answer questions. It is that they eventually need to hold secrets, read private...
A new arXiv paper proposes learning essential agent workflow states from a few passing traces, then validating future runs against those milestones instead of trusting self-reports.
A new benchmark with nearly ten thousand agents and 66,740 execution runs argues that your routing layer needs evidence from real runs, not just embeddings of marketing copy.
A new preprint tests whether smarter multi-agent pipeline layouts beat simple self-refinement for 1-3B code models. The answer is mostly no, and what actually moves the needle is execution feedback.
A new ACL 2026 paper reveals a hidden failure mode in RLHF pipelines: the reward model and the LLM can fail together, silently. ARES is designed to find and fix both.
A new arXiv preprint, LACE, modifies transformer attention so parallel reasoning threads exchange information mid-generation. We unpack what it shows, where it holds up, and where it doesn't.
A new preprint shows that telling a judge model its verdict might get a model retrained makes it roughly 30% less likely to flag unsafe content — and it has no idea it's doing it.
A Zhejiang University preprint argues that standard SFT can make downstream RL less effective, and proposes Group Fine-Tuning as a more stable bridge between imitation and reward-based post-training.
A new arXiv preprint introduces a policy-agnostic way to measure exploration and exploitation errors from agent trajectories alone, and finds that exploration failure, not exploitation, is what separates strong agents from weak ones.
A new preprint proposes Memory Worth, a simple two-counter signal for estimating which AI agent memories may have gone stale and could be candidates for suppression or review.
A consortium of leading AI safety institutions just published the first systematic methodology for analyzing AI agent logs — a seven-step pipeline from purpose definition to statistical analysis.
OpenKedge proposes restructuring AI agent mutation from reactive API calls to governed intent proposals — with cryptographic audit chains. Here's why the architectural shift matters for production systems.
A Princeton and UW preprint tests seven model families in structured advertising scenarios, and reports that many prioritize sponsored products over user welfare when prompted to do so.
A UCLA preprint argues that curating the right training data for reinforcement learning may matter more than scaling compute, and that human-annotated instruction datasets may already contain useful signal for improving reasoning beyond math and code in smaller models.
Anthropic's system card frames Claude Mythos Preview as a frontier cyber capability jump significant enough to justify restricted release instead of broad commercial deployment.
A training-free framework from UCLA, McGill, and HKUST dynamically switches between visual and textual table representations on the fly — achieving 4.87% better accuracy while cutting inference latency by a third.
A new ByteDance Seed preprint introduces XpertBench, a rubric-based benchmark with 1,346 expert-oriented tasks across 80 categories. On the paper's reported evaluation subset, even the top model reaches 66.20%.
Utah’s Legion pilot does not let AI broadly “do psychiatry”; it permits a tightly limited, closely audited workflow for some psychiatric medication refill renewals under human oversight.
A new preprint suggests document RAG can hurt reasoning models on hard benchmarks. Procedural retrieval from a 32M-recipe memory boosts accuracy by up to 19.2% in the paper's tested settings, with no fine-tuning.
A new arXiv paper shows shared-state LLM agents can fail without any attacker at all, leaking benign user conventions across sessions with contamination rates up to 70.7%.
A new arXiv paper introduces The Silicon Mirror, a dynamic framework that reduces LLM sycophancy by 85.7% on Claude Sonnet 4 using behavioral gating and adapter-based intervention.
A new paper from DigitalOcean proposes lightweight, model-free signals for triaging agent trajectories — achieving 82% informativeness rate with 1.52× efficiency over random sampling.
A 25,000-task experiment across 8 models and 256 agents shows that self-organizing LLM agents with minimal structure outperform centralized coordination by 14% and fully autonomous systems by 44%.
A training-free framework transfers reasoning ability from teacher to student through contextual experience — no weights modified, 22.9× cheaper than traditional distillation.
A training-free inference trick exposes the real bottleneck in masked diffusion language models. LogicDiff improves GSM8K accuracy from 22% to 60.7% without changing a single model weight.
A new LLM-driven multi-agent framework takes a plain English description and autonomously writes, runs, and debugs a full building-to-grid energy simulation — no manual coding required.
CMU researchers introduce CAID, a multi-agent coordination framework using git primitives that improves coding agent accuracy by up to 26.7% on complex software engineering tasks.
Google Research's TurboQuant pushes KV-cache compression near its practical limits. Here's what the paper actually claims, what matters, and what developers should not overstate.
An unsecured CMS exposed Anthropic's most powerful model yet. Here's what we know about Claude Mythos, the new Capybara tier, and why cybersecurity stocks just tanked.
François Chollet's latest benchmark pits frontier AI against interactive puzzle environments — and every model scores below 1% while humans score 100%.
A new paper introduces Session Risk Memory (SRM), a lightweight module that detects distributed multi-turn attacks on AI agents by tracking behavioral drift — with perfect F1 and zero false positives.
SFA sparsifies query and key features instead of tokens, achieving 2.5× speedup and 50% KV-cache reduction while matching dense attention quality. An ICLR 2026 paper breakdown.
ProMAS introduces proactive error forecasting for LLM-based multi-agent systems using Markov transition dynamics, detecting reasoning failures before they propagate by monitoring semantic velocity.
Meta FAIR introduces HyperAgents — self-referential AI agents that can modify their own improvement mechanisms. Results show meta-level improvements transfer across domains, from paper review to math grading.
OS-Themis introduces a multi-agent critic framework that decomposes GUI agent evaluation into milestone verification and verdict calibration, achieving 18.8% accuracy gains over baselines for RL-trained agents.
A new paper introduces Helium, a workflow-aware LLM serving framework that treats agentic workloads like database query plans. Up to 1.56x speedup by eliminating redundant compute across chained LLM calls.
UCPOF uses first-token uncertainty to cut RAG retrieval calls by 50% while beating always-on RAG accuracy by 5.75%. A practical framework for smarter prompt optimization.
A new framework compresses agent memory into 15 latent vectors with near-lossless reconstruction. Here's how NextMem's autoregressive autoencoder works and why it matters.
MiroThinker-H1 introduces verification-centric reasoning for AI research agents, achieving state-of-the-art results on BrowseComp, GAIA, and more — while using fewer interaction steps.
MiniMax M2.7 participated in its own development — building skills, running RL experiments, and optimizing its own scaffolding for real-world engineering tasks.
AMRO-S uses ant colony optimization to route tasks across multiple LLMs — delivering 4.7× faster throughput, better accuracy than GPT-4o, and full interpretability.
Princeton's OpenClaw-RL framework turns every conversation, command, and interaction into a live training signal — no labeled datasets required. Here's how it works.
Learn how to build policy engines, approval workflows, and auditable agent execution around OpenClaw to safely deploy AI agents in enterprise environments.
New research from Oxford and Parameter Lab proves that your choice of AI agent framework impacts performance just as much as your choice of model. Here's what MASEval found.
Exact costs to self-host an AI assistant in 2026. VPS comparison table, LLM API pricing by model, the free-tier $0/month path, and the recommended $5–8/month setup.
New IEEE CON 2026 research shows human oversight in AI isn't a single checkpoint — it's continuous, negotiated work across the entire system lifecycle.
New research tests whether giving an LLM step-by-step environmental feedback improves planning. The result: a 3% gain at 5.7x the cost. The real insight is about feedback quality.
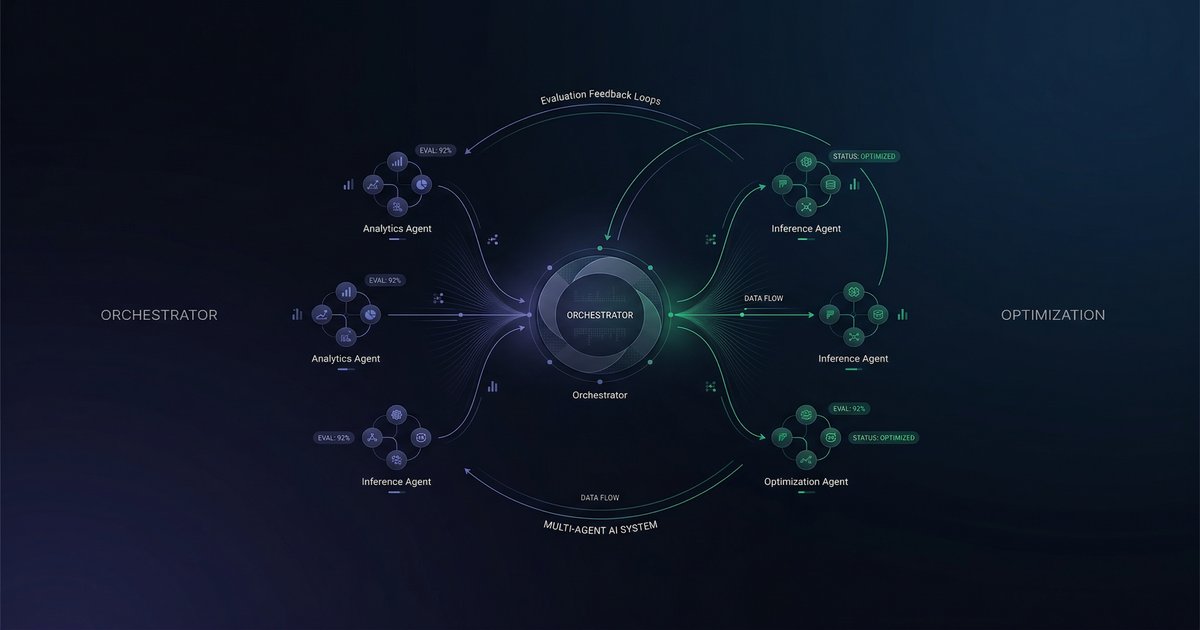
A new ICLR 2026 paper from DoorDash reveals how to evaluate and optimize multi-agent AI systems end-to-end — with calibrated judges, binary rubrics, and the MAMUT framework.
What is Model Context Protocol? A practical guide to MCP servers — what they do, how they work, real servers you can use today, and how to set one up in 10 minutes.
A deep dive into SuperLocalMemory, a new open-source system that defends AI agents against memory poisoning using Bayesian trust scoring and local-first architecture.
Your agent has a 200K token context window, yet it forgets critical information mid-conversation. Why context management matters more than context size.
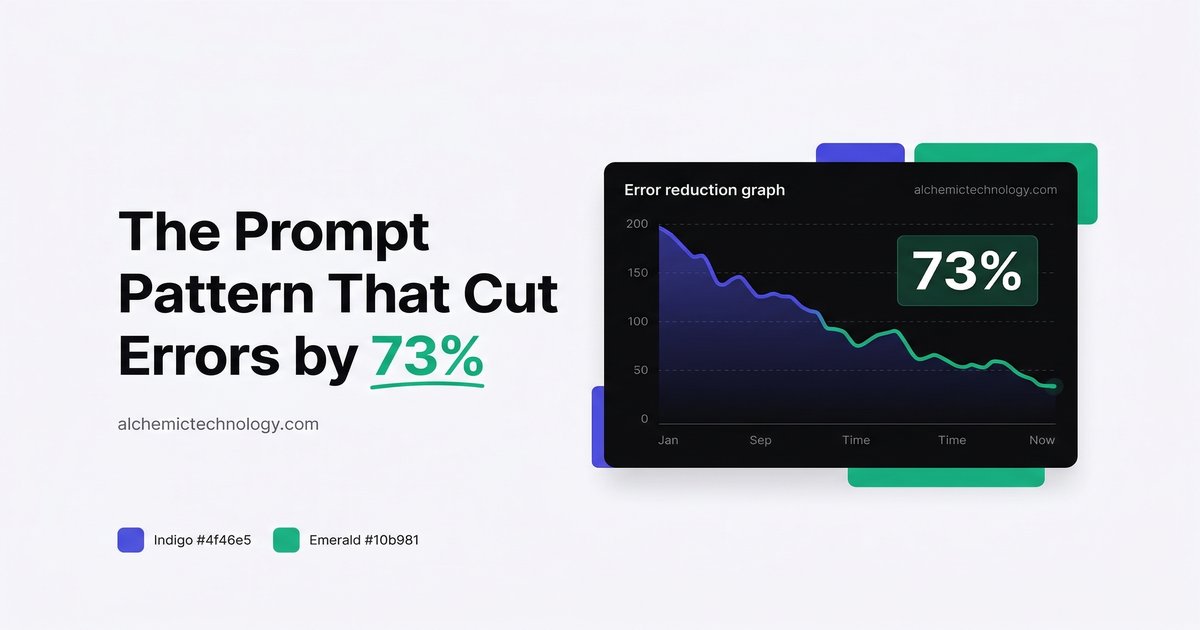
After A/B testing 12 prompt engineering patterns, we found one that consistently reduced agent errors by nearly three-quarters. The validation loop pattern that works.
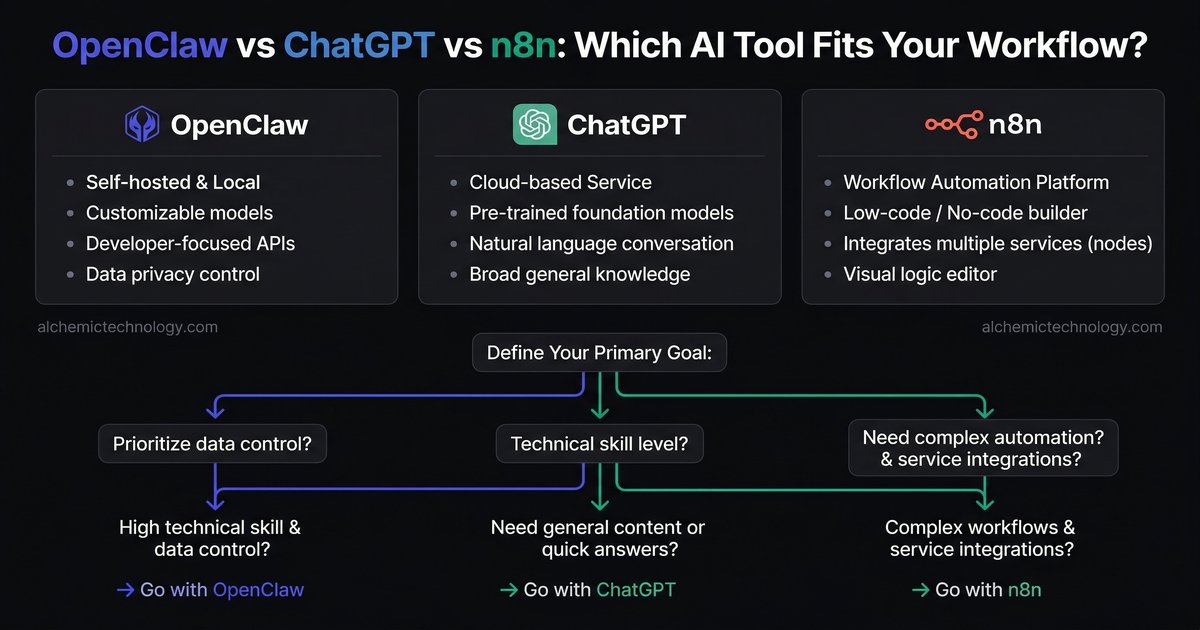
The OpenClaw Field Guide walks you through setting up, configuring, and running AI agents on your own infrastructure. Multi-model routing, cron automation, sub-agent teams, security hardening — everything in one reference.