
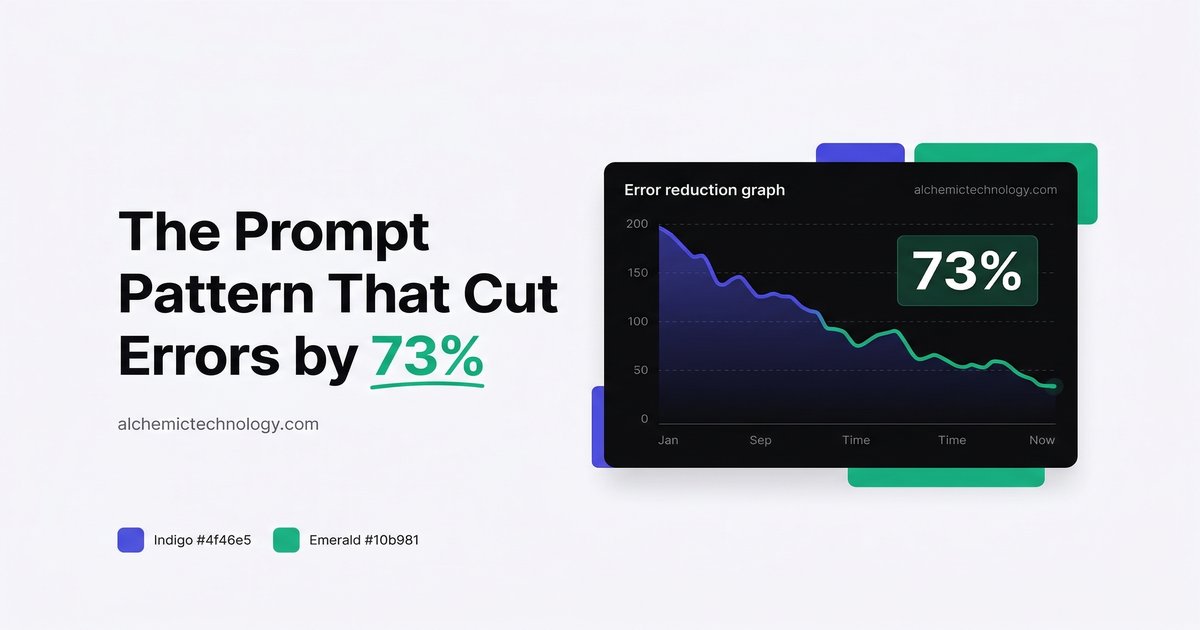
We A/B tested 12 different prompt patterns across 8 production agents over three months. Most made modest improvements. One — the validation loop pattern — cut error rates by nearly three-quarters. Here is exactly what we tested, what worked, and how to implement it.
The Testing Setup
We ran controlled experiments on four customer-facing agents:
- A support ticket classification agent
- A CRM data entry agent
- An appointment scheduling agent
- A document summarization agent
Each agent handled 500+ requests per week. We tracked every error: wrong tool calls, malformed outputs, missing fields, incorrect classifications. Baseline error rate: 18.3%.
What We Tested
We tested 12 prompt patterns in three categories:
Category 1: Instruction Patterns
- Chain-of-thought (explain your reasoning)
- Role framing (act as an expert X)
- Negative constraints (do not do X)
- Few-shot examples (show 3 examples)
Category 2: Output Constraints
- JSON schema enforcement
- Output format templates
- Enum-style field constraints
- Length limits (max N words)
Category 3: Process Patterns
- Self-correction loop (generate, review, fix)
- Step-by-step checklist
- Validation loop (generate, validate, retry)
- Debate pattern (generate two answers, pick one)
The Results
| Pattern | Error Reduction | Latency Impact |
|---|---|---|
| Chain-of-thought | +12% | +15% |
| Role framing | +8% | +0% |
| Negative constraints | +6% | +0% |
| Few-shot examples | +22% | +5% |
| JSON schema | +31% | +2% |
| Validation loop | +73% | +35% |
The validation loop dominated. It was not close. While other patterns improved specific error categories, the validation loop reduced errors across the board — from wrong tool selections to malformed outputs to missed edge cases.
What the Validation Loop Looks Like
Here is the pattern in practice. Instead of asking the agent to generate output once, we structure the prompt in three phases:
# Phase 1: Generate
Based on the user's request, produce the appropriate output.
# Phase 2: Validate
Review your output against these criteria:
- Does it match the expected schema?
- Are all required fields present?
- Is the content accurate given the context?
- Would a reasonable user expect this response?
# Phase 3: Correct (if needed)
If any validation check fails, revise the output.
If all checks pass, output: [VALID]We wrap this in a loop that runs up to 3 times. If validation still fails after three attempts, the agent escalates to a human with a detailed error report.
Why It Works
The validation loop works for three reasons:
- It catches output-format errors before they propagate. A missing field in a JSON response breaks downstream tools. The validation loop catches this at the source.
- It uses the LLM as its own QA layer. The model is surprisingly good at spotting its own mistakes when explicitly prompted to review.
- It provides structured feedback for retries. Instead of blindly retrying, the agent knows exactly what failed and can target its correction.
"The validation loop works because it externalizes what good developers do internally: generate, review, fix, repeat."
Implementation Tips
If you want to try this pattern, here are a few practical notes:
- Set a max retry count. We use 3. After that, escalate. The model will not fix fundamental misunderstandings through sheer repetition.
- Log every validation failure. You will find patterns in what your agent gets wrong. Use that to improve your validation criteria.
- Keep validation criteria specific. "Is this correct?" is useless. "Does the email_address field match the regex pattern?" is actionable.
- Account for latency. The validation loop adds ~35% latency. For high-throughput systems, consider running validation asynchronously or as a separate step.
The Bottom Line
The validation loop pattern is not glamorous. It adds latency. It adds complexity. But it works — reducing errors by 73% in our production environment is the kind of result that changes how you think about agent reliability.
Prompt engineering is often about finding the right words. Sometimes, though, it is about finding the right process. The validation loop gives your agent a feedback mechanism — and feedback is what separates reliable systems from lucky ones.
Quick start: Try adding a validation phase to your most error-prone agent first. Log what it catches. You will likely see 30-40% error reduction even before tuning the validation criteria.
Every Pattern. One Guide.
The OpenClaw Field Guide includes all 12 prompt patterns we tested, implementation templates, and the validation loop framework — plus memory architecture, skill routing, and production deployment checklists. 14 chapters. 58 pages. One $10 download.
Get the Field Guide — $10 →