
A tool-using agent starts out simple. Give the model a calculator, a database query function, a few scripts, maybe a browser, and let it route between them. The trouble arrives later, after the system has learned enough useful procedures that the tool library itself becomes the bottleneck. A flat list of skills is fine when there are ten of them. At a hundred, the planner spends more of its scarce context budget reading tools than solving the task.
That is the problem CoCoDA takes seriously. The paper, CoCoDA: Co-evolving Compositional DAG for Tool-Augmented Agents, argues that tool libraries should not be treated as loose text memories. They are executable structures. A tool has input and output types. It depends on other tools. It has behavior that can be specified and examples that show how it works. CoCoDA uses those properties to organize an agent's tool library as a compositional code DAG, then trains the planner and the library to improve together.
The practical insight is straightforward: if an agent repeatedly solves the same multi-step subproblem, that subproblem should become a validated composite tool. But if every new composite is just appended to a text index, the library gets bigger and retrieval gets worse. CoCoDA tries to get both sides right. It grows the library when successful trajectories reveal reusable work, and it uses the graph structure of executable tools to keep retrieval bounded.
What CoCoDA Changes
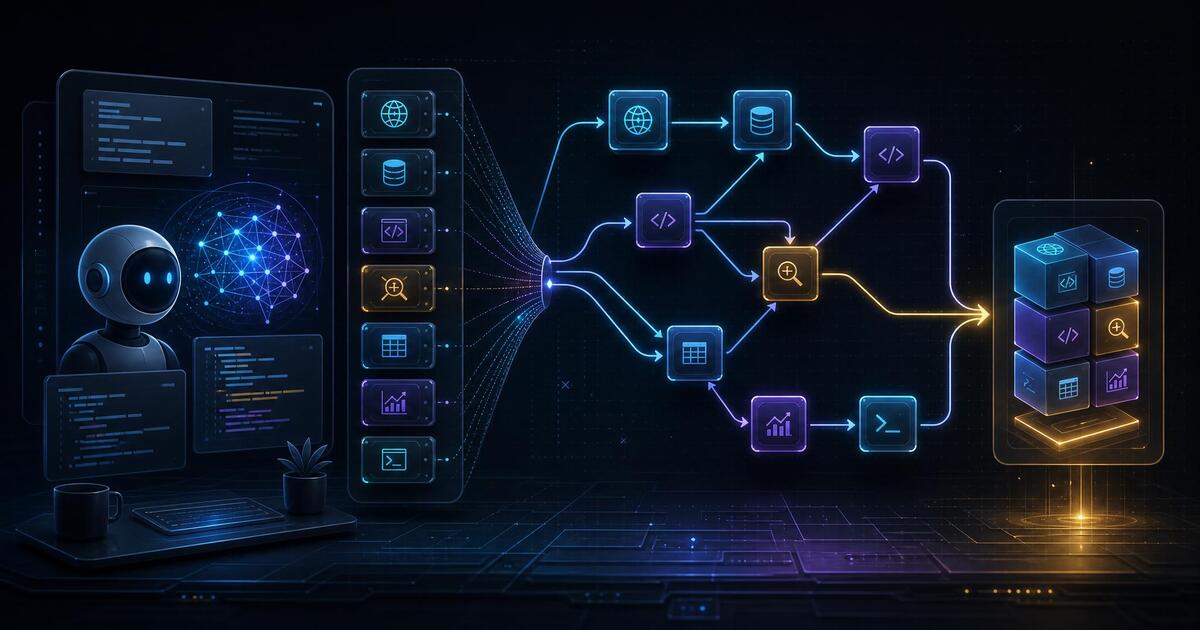
The library in CoCoDA is a directed acyclic graph. Nodes are primitive or composite tools. Edges represent invocation dependencies. Each node carries four records: a typed signature, a description, pre/post-condition specifications, and worked examples. That gives the retrieval system several cheap-to-expensive filters instead of one big semantic search over every possible tool.
The retrieval path is called Typed DAG Retrieval. First, CoCoDA uses symbolic signature pruning to remove tools whose input and output types cannot satisfy the current subgoal. That stage does not require a language-model judgment. Next, it ranks descriptions among the surviving candidates, using the DAG to move toward a composite tool when one can cover the subgoal or down toward primitives when the composite is too broad. Then it applies specification filtering, checking whether the tool's preconditions can be met and whether its postconditions imply the desired result. Only at the end does it use examples to break close ties.
This order matters. Many production agent stacks do the expensive thing first: embed everything, retrieve a broad candidate set, and let the model reason through the mess. CoCoDA's bet is that executable code already gives us stronger structure. Types, dependencies, and contracts are not decoration. They are retrieval controls.
The Co-Evolution Loop
The second half of the paper is about keeping the planner and the library aligned. During training, the planner rolls out tool-using trajectories. Successful trajectories are sent to a fixed teacher abstractor, which proposes new composite tools. CoCoDA does not blindly accept those proposals. Its InsertTool step accepts a candidate only when it preserves acyclicity and passes dependency and specification checks.
Once the composite exists, the planner is trained with a graph-aware reward. The reward gives credit for using a composite tool that saves primitive calls, but only in the context of a verified successful result. That distinction is important. Rewarding shorter tool traces without correctness would invite shortcutting. CoCoDA's formulation treats the composite as valuable when it is a behavior-preserving replacement for a longer primitive sequence.
For practitioners, this is the part worth stealing even if nobody adopts the full paper. A mature agent platform should have a promotion path from repeated successful traces to reusable tools, but it should also have gates: deterministic task success, dependency checks, interface checks, and rollback if the abstraction is wrong. Otherwise a skill library becomes an unreviewed pile of prompt snippets.
What The Results Say
The paper evaluates CoCoDA with Qwen3-32B as a teacher and Qwen3 student models at 0.6B, 1.7B, 4B, and 8B. The benchmark suite covers six tasks: GSM8K and MATH for math/logical reasoning, WikiTableQuestions and FinQA for tabular analysis, and EvalPlus plus MBPP for code tasks. The authors use deterministic code-based verification across the benchmark categories, including numeric, symbolic, SQL, program, and unit-test checks.
In the reported main table, CoCoDA is the top student method in every listed size-and-benchmark cell. At 8B, it reports 93.67 on GSM8K and 63.18 on MATH. The paper lists the 32B teacher at 93.40 and 61.62 on those same benchmarks, so the authors describe the 8B student as matching or exceeding the teacher on math/logical tasks. At 4B, CoCoDA reports 92.64 on GSM8K and 73.42 on MBPP, compared with 87.79 and 67.00 for the 4B chain-of-thought student baseline.
The ablations are more useful than the headline table. On the 4B student, removing the compositional tool DAG costs an average 3.49 points. Removing Typed DAG Retrieval costs 1.79 points. Removing the graph-aware reward costs 1.40 points. Removing all three costs 5.18 points. That pattern supports the paper's central claim: the value is not just having tools, or just retrieving them, or just rewarding tool use. The value comes from coupling executable structure, retrieval, and training.
The paper also reports that library size and average compositional depth rise sharply during the first 150 GRPO steps and then saturate. That is a good sign for the intended use case. A useful self-growing tool library should not expand forever just because the agent keeps seeing tasks. It should discover reusable abstractions, reuse them, and slow down as the obvious patterns are captured.
The Caveats
This is still a research system. The source link in the paper points to an anonymous 4open.science repository, which is weaker than a stable project home. The results here are paper-reported and were not independently reproduced for this post. The method also depends heavily on verification. CoCoDA's benchmark setup is friendly to deterministic checks: exact numeric answers, symbolic equivalence, SQL execution, numeric programs, and unit tests. Many real workflows do not have verifiers that clean.
There is also judge risk inside the retrieval stack. The paper's hyperparameter table describes the specification check as LLM-judged on declared preconditions, postconditions, and complexity. That may be reasonable in the experiment, but production systems would want stronger checks where possible: type validation, executable tests, schema constraints, recorded examples, and human review for tools that can affect customers or money.
Compute is another practical constraint. The reported total GPU-hours are 35 for 0.6B, 55 for 1.7B, 87 for 4B, and 98 for 8B. That is not absurd for research, but it is not a free nightly maintenance task for most teams.
What To Do With It
CoCoDA is best read as a design pattern for serious agent systems. Stop treating skills as flat documents. Store tools as typed, testable, composable units. Make dependencies explicit. Put cheap symbolic filters before expensive model calls. Promote repeated successful traces into composite tools only after verification. Reward the agent for using abstractions that preserve behavior and reduce work, not for merely looking concise.
The bigger lesson is that agent memory and tool use are converging. A skill library is not just recall. It is operational memory: executable experience that should become easier to retrieve and safer to reuse over time. CoCoDA gives that idea a concrete shape. The details may change, but the direction feels right: agents will need libraries that grow, prune, validate, and compose with the same discipline we expect from software systems.
Sources
Build Agents That Prove Their Work
If you are wiring agent workflows into real operations, Alchemic can help design the checkpoints, traces, and validation gates that keep automation honest.
Get the Field Guide - $10 ->