
A watermark is a useful signal, but it is a thin one. It can help answer, “Was this asset generated or altered by a known system?” It does not answer the harder operational questions that show up in real organizations: Which prompt, model, editor, dataset, stock asset, approval step, export path, and publishing system touched this file before it reached a customer?
That is the difference between a label and a chain of custody.
As generative AI moves from experiments into marketing, product documentation, sales enablement, training, customer support, and executive communications, the trust problem becomes less about spotting one fake image and more about preserving context across a workflow. An enterprise does not merely need to know whether a final JPEG has an AI marker. It needs to know whether the content traveled through an accountable process.
The standards ecosystem is starting to reflect that. The [C2PA guidance for AI and machine learning](https://spec.c2pa.org/specifications/specifications/2.4/ai-ml/ai_ml.html) describes Content Credentials as useful not only for finished media, but also for training and inference data, software packages, models, fine-tuned adapters, outputs, dataset partitions, and release chains. That is a much broader idea than a badge on a social post. It is provenance for the materials and machinery of AI work.
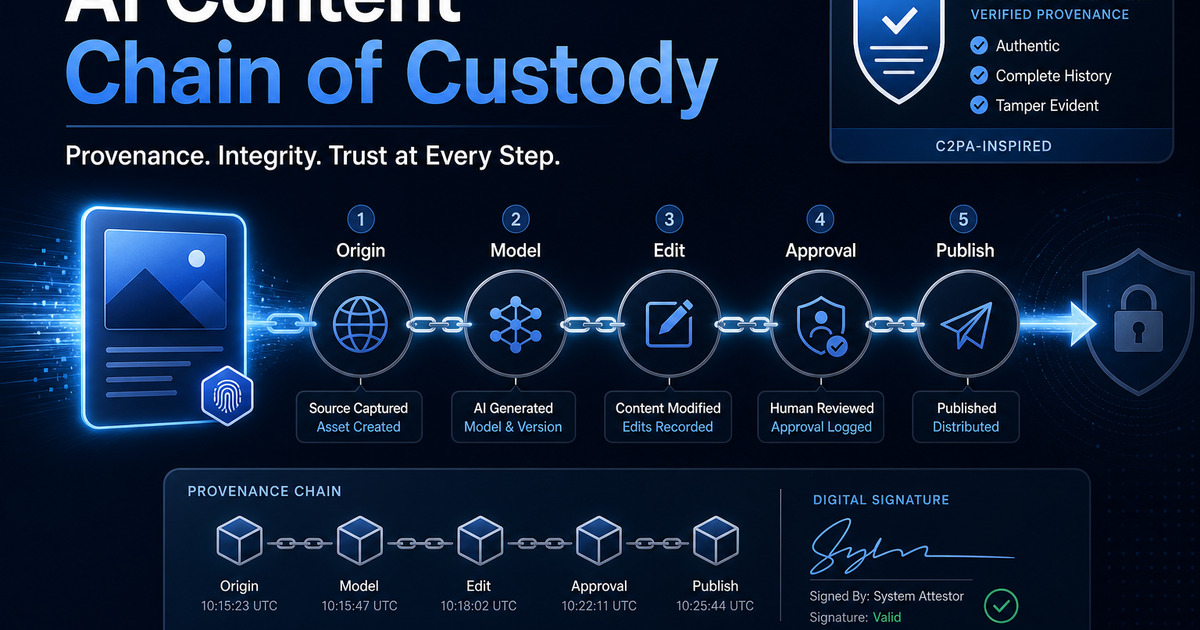
This matters because AI content is rarely a single act of creation. A campaign image may start with a product photo, move through an image generator, get edited by a designer, pass through brand review, be resized by a DAM, and then be uploaded to a CMS that strips metadata. A training video may combine synthetic voice, licensed footage, human narration, and post-production edits. A model artifact may be assembled from multiple files, adapters, libraries, and dataset slices. Each handoff is a place where context can be added, lost, or falsified.
A chain-of-custody mindset asks teams to make those handoffs visible.
Content Credentials help by binding signed claims to an asset. Those claims can describe origin, ingredients, edits, tools, and other provenance information. The joint cybersecurity information sheet from the NSA, ASD’s ACSC, CCCS, and NCSC-UK describes Content Credentials as cryptographically signed metadata that provides context about a media asset’s provenance. It also makes an important caution: provenance does not prove that content is true. It gives people and systems more context for judging authenticity.
That distinction is critical. A signed credential can say a video came from a particular camera or an image was generated by a particular tool. It cannot, by itself, prove the scene is fair, the caption is honest, the policy use is appropriate, or the organization should publish it. Provenance is evidence, not judgment.
This is why “just watermark it” is too small a plan. Watermarks can be stripped, transformed, or ignored. The cybersecurity guidance discusses durable Content Credentials that combine signed metadata with additional preservation mechanisms such as watermarking and robust media fingerprinting, precisely because real distribution paths are messy. Metadata gets lost. Platforms recompress files. People screenshot things. Agencies export variants. Social networks transform assets. If the organization cares about high-risk media, it needs a recovery strategy, not just a tag.
The [Content Authenticity Initiative’s 2026 state post](https://contentauthenticity.org/blog/the-state-of-content-authenticity-in-2026) frames the broader shift well: Content Credentials are becoming something created at capture, carried through professional workflows, verified across platforms, and understood by end users. The strongest provenance begins at origin and survives edits, platforms, and contexts. In other words, the trust layer has to live where the work happens.
For enterprise teams, the practical question is not whether C2PA is perfect. It is how to design a workflow that can benefit from provenance where it exists and avoid pretending that absence of provenance is a complete verdict. The cybersecurity guidance explicitly warns that lack of provenance information should not automatically make media untrustworthy. Many legitimate assets will still arrive without credentials. The right response is risk-based review, not binary superstition.
A workable operating model starts at creation. If your team generates an image, edits a video, records an executive message, or packages a model artifact, provenance should begin there. Capture the tool, source asset, model or system identity where appropriate, and the major transformation. Do not wait until the final export, when the original context has already been flattened into a finished deliverable.
Next, track ingredients. For creative work, that means source photos, stock assets, generated layers, audio stems, human edits, and approval versions. For AI systems work, the C2PA AI/ML guidance points toward similar thinking for datasets, software, model files, adapters, and release chains. If a model or dataset is multi-file, provenance may need to point to the ingredients rather than pretending there is one magic file that represents the whole thing.
Then test the boring plumbing. Does your DAM preserve credentials? Does your CMS strip them? What happens when a designer exports a resized version? What does the social publishing tool keep or remove? Can reviewers see the provenance before approval, or only after publication? These questions are not glamorous, but they determine whether provenance is real infrastructure or a slide in a governance deck.
Governance also needs named authority. Who is allowed to sign on behalf of the organization? Which claims are permitted? What happens when an asset is corrected, withdrawn, or replaced? What must a reviewer check before approving AI-assisted content? How should employees handle external media with no credentials, broken credentials, or credentials that show unexpected edits? Without those rules, credentials become another field nobody reads.
NIST’s [Generative AI Profile](https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf) is useful here because it places generative AI risk across the lifecycle: design, deployment, operation, monitoring, maintenance, and decommissioning. It also treats risk sources broadly, including training data, fine-tuning, retrieval, inputs, outputs, third-party components, misuse, and human-AI interaction. Provenance belongs in that lifecycle view. It is not only a media feature; it is a risk-management control.
The companies that get this right will not talk about provenance as a single badge. They will treat it like audit logging for content. Every important asset should carry enough history for a future reviewer to answer: where did this come from, what changed, who approved it, and what should I trust it for?
That is the real promise of Content Credentials and related standards. Not that every piece of media becomes self-evidently true. Not that deception disappears. Not that a watermark saves the internet.
The promise is more practical and more valuable: AI work can become accountable enough to operate.
For teams building with AI, that is the bar to clear. Do not ask whether the final file has a mark. Ask whether your pipeline can preserve a chain of custody from intent to publication. If it cannot, the weak point is not the model. It is the workflow around it.
Sources
- https://spec.c2pa.org/specifications/specifications/2.4/ai-ml/ai_ml.html
- https://contentauthenticity.org/blog/the-state-of-content-authenticity-in-2026
- https://media.defense.gov/2025/Jan/29/2003634788/-1/-1/1/CSI-CONTENT-CREDENTIALS.PDF
- https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
Build Agents That Prove Their Work
If you are wiring agent workflows into real operations, Alchemic can help design the checkpoints, traces, and validation gates that keep automation honest.
Get the Field Guide - $10 ->