
The easiest agent demo is the clean one: a user asks for something, the model chooses the right tool, the tool returns a valid response, and the agent neatly completes the task. That demo is useful. It proves the path exists.
It does not prove the system is ready.
Production agents live in environments where APIs time out, permissions change, documents go stale, filenames lie, records are duplicated, and a tool can return a perfectly valid JSON object containing the wrong business fact. If the agent only knows how to follow the happy path, reliability is not a property of the system. It is an accident of the day’s inputs.
That is why the next serious release gate for agentic systems should look less like a leaderboard and more like an emergency drill.
A June 2026 paper, [“When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents”](https://arxiv.org/html/2606.05806v1), makes the gap explicit. The authors argue that many tool-integrated reasoning evaluations still measure idealized happy paths, while real agents have to recover from broken or misleading tools. Their benchmark, ToolMaze, tests agents across two dimensions: the complexity of the tool-call graph and the type of perturbation introduced into that graph.
The distinction that matters most for builders is simple: not all failures announce themselves.
Some failures are explicit. A service returns a 404, a 429, a timeout, or a structured exception. These are not easy, but at least the system knows something went wrong. Other failures are implicit. The tool returns an object in the expected shape, but the contents are semantically corrupted: a negative inventory count, a stale price, a nonsense date, or a plausible answer from the wrong source. Those failures are harder because the agent has to verify meaning, not just parse syntax.
ToolMaze also separates transient failures from permanent ones. A transient explicit error may deserve a retry. A permanent explicit error may require a reroute. A transient implicit corruption may require rechecking the source. A permanent implicit corruption may require abandoning that path entirely and escalating. Those are different behaviors, and a production agent should not treat them all as “try again until the turn budget runs out.”
This fits a broader shift in agent research. The survey [“The Evolution of Tool Use in LLM Agents”](https://arxiv.org/html/2603.22862v2) describes how the field has moved from single-tool invocation toward long-horizon, multi-tool orchestration. In a real workflow, the problem is not merely whether the model can call get_customer_record. The problem is whether it can maintain state, interpret tool feedback, re-plan under changing conditions, control cost and latency, verify intermediate results, and stop safely when the environment no longer supports the requested action.
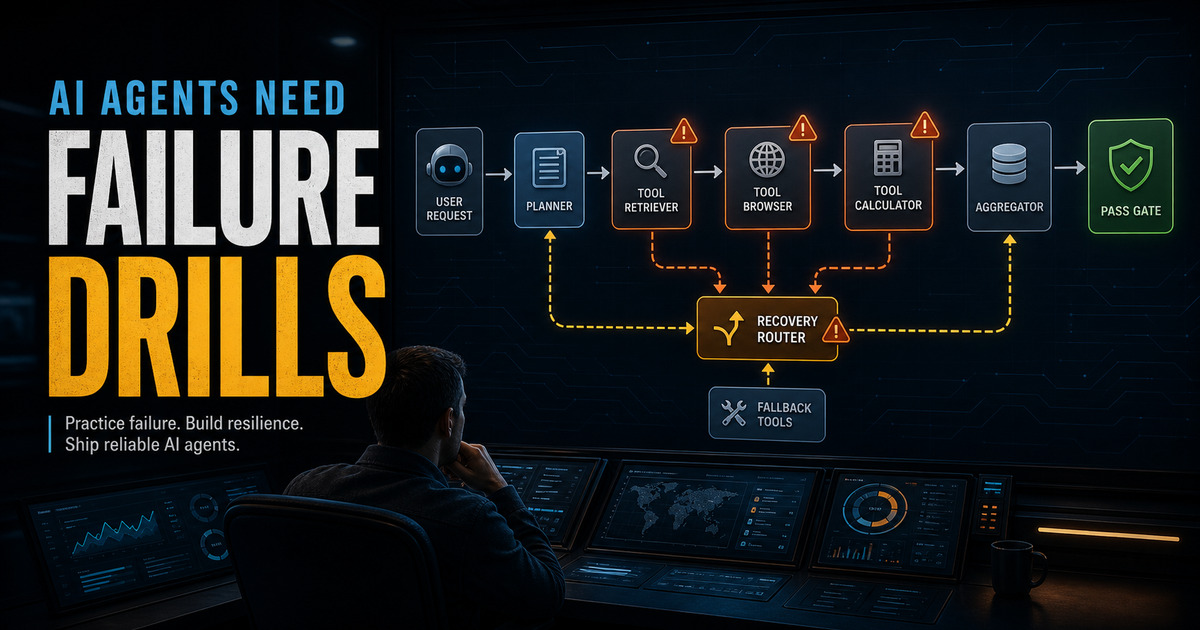
That means agent QA needs to become graph-aware. Before launching an agent, map the workflow it is allowed to traverse: tools, states, dependencies, side effects, human handoff points, and terminal conditions. Then inject failures into that graph on purpose.
A practical failure-drill suite should include at least five classes of exercises.
First, inject explicit service failures. Make the billing API return a timeout. Make the search endpoint rate-limit the agent. Make an integration return a permission error. The drill is not just whether the agent eventually succeeds; it is whether it retries the right number of times, preserves idempotency, avoids duplicate side effects, and explains the degraded path in an audit trail.
Second, inject implicit corruptions. Return a valid schema with a stale account status. Swap one file version for another. Provide a plausible but contradictory value from a secondary system. The agent should not blindly accept the first well-formed response. It should cross-check high-impact facts, notice contradictions, and ask for help when confidence is not earned.
Third, test permanent dead ends. Some paths should not be recoverable. If a required authorization is missing, the correct answer may be to stop. If all available sources disagree, the correct answer may be to produce no final action. This is uncomfortable for teams that want autonomous completion, but graceful refusal is part of reliability.
Fourth, include workspace failures, not only API failures. [Workspace-Bench 1.0](https://arxiv.org/html/2605.03596v1) shows why this matters. Its authors evaluate agents in large, heterogeneous workspaces with thousands of files, many file types, and dependency-rich tasks. They report that current agents remain far from reliable workspace learning, with the best result at 68.7% versus an 80.7% human result, and an average agent performance of 47.4% across tested configurations. The bottlenecks include heterogeneous file understanding and lineage tracing. In plain language: agents often struggle before the API call, because they do not know which messy piece of workplace evidence is the right one.
So a failure drill should include stale drafts, renamed attachments, duplicated exports, partial spreadsheets, missing dependencies, and conflicting lineage. If the agent cannot explain why it trusted a file, it should not be trusted to act on that file.
Fifth, measure recovery quality separately from final success. A pass/fail task score is too coarse. Track whether the agent detected the anomaly, chose the right recovery policy, avoided repeated failing calls, contained side effects, preserved user intent, escalated with useful context, and stayed within acceptable cost and latency. A system that succeeds after thrashing through twenty unnecessary calls may still be operationally unsafe.
This is also where architecture discipline matters. Anthropic’s [“Building Effective AI Agents”](https://www.anthropic.com/research/building-effective-agents) argues for simple, composable, transparent systems and warns that agentic complexity trades latency and cost for performance. That guidance is especially relevant under failure. If a path is predictable and high-stakes, it may belong in a workflow with explicit gates rather than in an open-ended autonomous loop. If an agent is allowed to choose its path, the allowed exits, verification checks, and escalation thresholds need to be visible to operators.
The goal is not to make every agent paranoid. The goal is to make its failure behavior rehearsed.
For enterprise teams, this changes the release conversation. Do not ask only, “Can the agent complete the demo?” Ask: What happens when the preferred tool is down? What happens when the fallback returns a plausible lie? What happens when the workspace contains three versions of the same contract? What happens when retrying would create a duplicate action? What evidence does the agent leave behind for the operator who has to clean up the mess?
A reliable agent is not one that never sees a broken tool. It is one whose behavior under broken tools has already been tested, scored, and bounded.
Happy-path demos show what is possible. Failure drills show what is safe enough to run.
Sources
- https://arxiv.org/html/2606.05806v1
- https://arxiv.org/html/2603.22862v2
- https://arxiv.org/html/2605.03596v1
- https://www.anthropic.com/research/building-effective-agents
Build Agents That Prove Their Work
If you are wiring agent workflows into real operations, Alchemic can help design the checkpoints, traces, and validation gates that keep automation honest.
Get the Field Guide - $10 ->